Back
Activault: Scalable, Efficient, and Fast Model Activation Storage
Key Results
- Training interpreter models on frontier LLMs requires collecting and storing billions of activations (analogous to the model's "mental state" at inference time), which amounts to several petabytes of data - prohibitively expensive for most researchers.
- To this end, we introduce Activault, an activation data engine designed to dramatically reduce the costs associated with training interpreter models by leveraging S3 object storage.
- Activault facilitates reproducibility & shareability within interpretability research and empowers researchers to perform high-throughput experiments efficiently at scale.
- With Activault, we reduce the cost of activation data for training interpreter models by at least ~4-8x while maintaining peak efficiency & throughput.
- Activault can collect 10 billion tokens of activations for 6 layers of Llama 3.3 70B in 3.5 days on one H100 node.
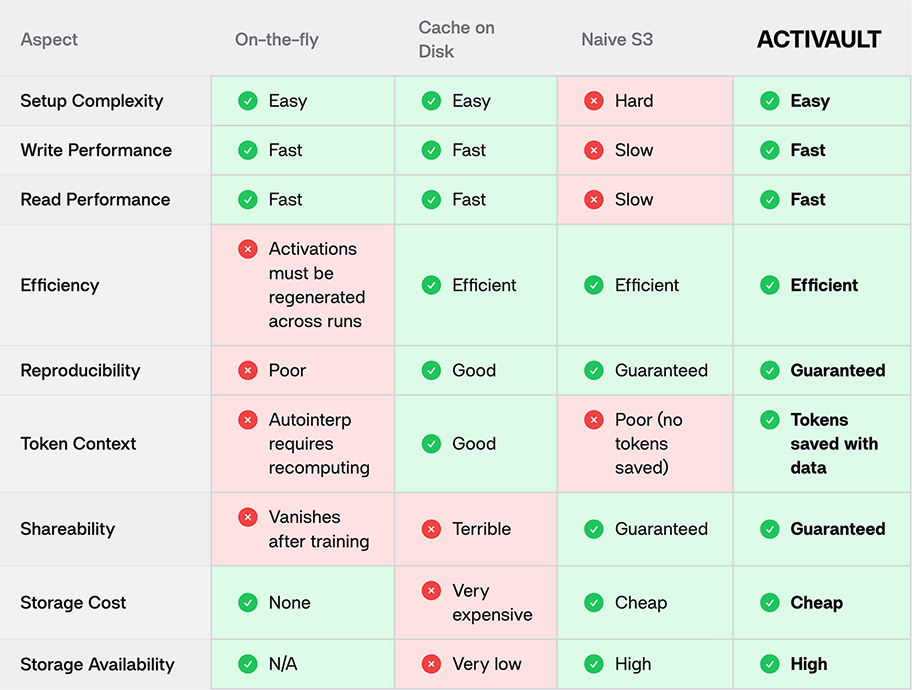 Comparison of Different Activation Storage Approaches.
Comparison of Different Activation Storage Approaches.
| Aspect | On-the-fly | Cache on Disk | Naive S3 | ACTIVAULT |
|---|---|---|---|---|
| Setup Complexity | Easy | Easy | Hard | Easy |
| Write Performance | Fast | Fast | Slow | Fast |
| Read Performance | Fast | Fast | Slow | Fast |
| Efficiency | Activations must be regenerated across runs | Efficient | Efficient | Efficient |
| Reproducibility | Poor | Good | Guaranteed | Guaranteed |
| Token Context | Autointerp requires recomputing | Good | Poor (no tokens saved) | Tokens saved with data |
| Shareability | Vanishes after training | Terrible | Guaranteed | Guaranteed |
| Storage Cost | None | Very expensive | Cheap | Cheap |
| Storage Availability | N/A | Very low | High | High |
We release Activault code here and welcome contributions!
Introduction
Today's open-weight frontier models have reached unprecedented performance levels, with reasoning and non-reasoning architectures matching or surpassing proprietary closed-source models on benchmarks[1][2]. Currently, frontier models are treated as black boxes—vast input-output systems that process data and produce outputs without interpretability, transparency, or attribution. As models continue to advance and find broader application, reverse-engineering their inner workings becomes vital for downstream reliability and efficacy.
These models encode immense amounts of information within their internal activations—dense, opaque computational flows analogous to a model's "mental state"—but interpreter models can dissect these activations into comprehensible, causal building blocks known as features.
Interpreting activations
Among current approaches for feature learning from model activations, the most prominent is the sparse autoencoder (SAE) [3]. SAEs are the most common mechanistic interpretability method capable of scaling to frontier-scale models. The SAE literature explores enhancements in base architecture, optimization methods, and application scenarios, as well as their intrinsic limitations [4] [5] [6] [7]. Nonetheless, a significant bottleneck across all existing feature learning techniques that scale to models with 100B+ parameters is their extremely high training cost.
For instance, training an SAE typically requires processing activations from 100–1,000× fewer tokens than the base model, and feature quality depends heavily on activation volume, necessitating extensive forward passes. This cost multiplies when deploying SAEs across layers, model variants, or metaSAEs, and is further exacerbated by hyperparameter sweeps and configuration tuning.
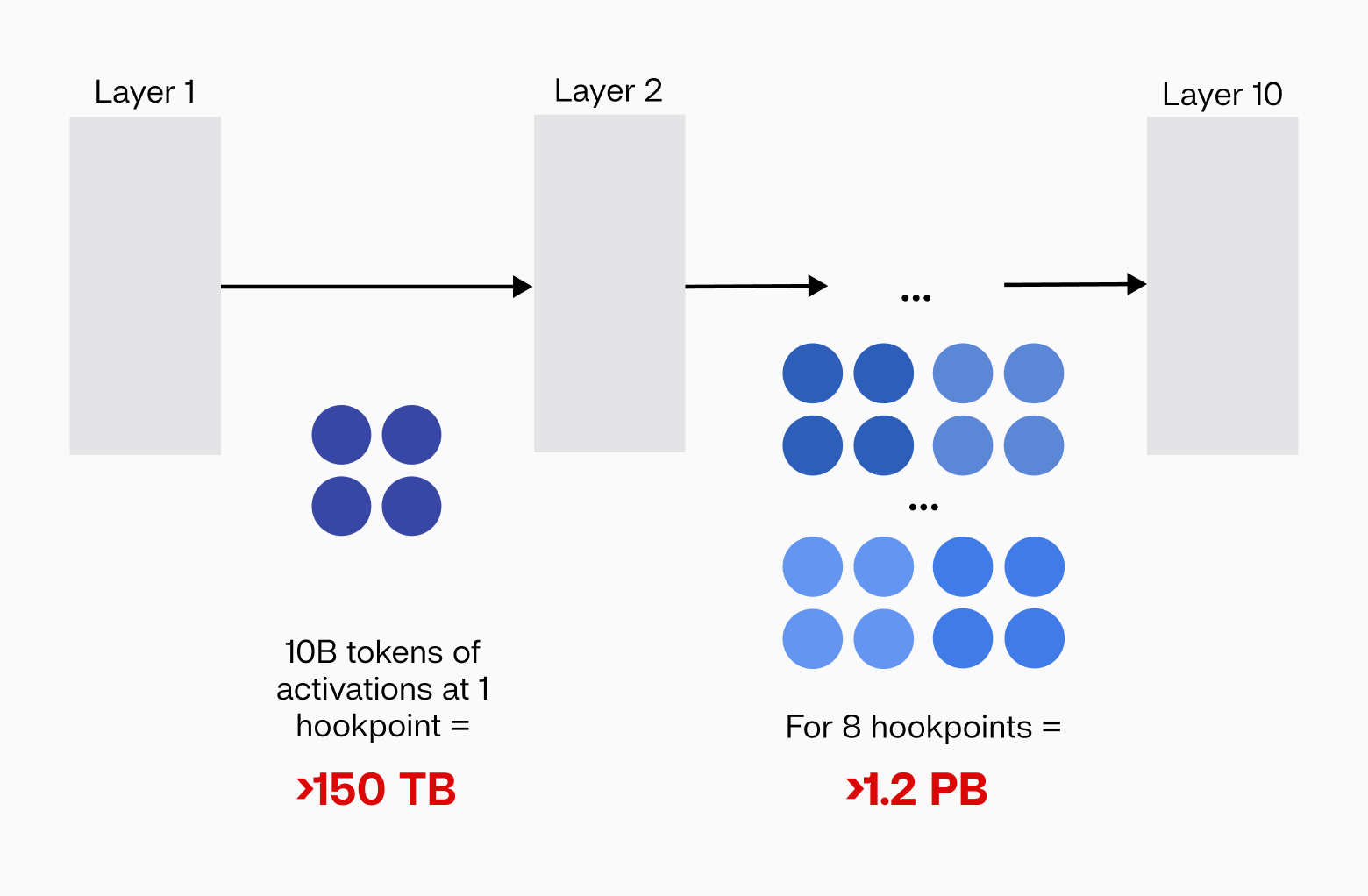 FIGURE 1: Training interpreter models on just a single model (Llama 3.3 70B) requires processing massive amounts of activations, making it prohibitively expensive for most researchers.
FIGURE 1: Training interpreter models on just a single model (Llama 3.3 70B) requires processing massive amounts of activations, making it prohibitively expensive for most researchers.
To illustrate the scale of this challenge: training an SAE for the Llama 3.3 70B model requires processing >10 billion tokens of activations, translating to roughly 150 TB of data in bfloat16 precision. With 80 layers and multiple hookpoints, comprehensively decomposing the model into interpretable features quickly balloons into petabyte-scale computations. For example, training just 8 SAEs requires around 1.2 PiB of activations—a resource-intensive requirement that severely restricts accessibility for most researchers and practitioners. Consequently, despite widespread awareness of SAEs within the interpretability community, there is a noticeable scarcity of publicly available, high-quality interpreter models for large models.
Addressing the bottleneck
Addressing these barriers is critical for fostering broader and more collaborative interpretability science around frontier models. Specifically, the current norm involves either recomputing activations through repeated forward passes of language models for each individual SAE [8] [9], incurring immense computational overhead, or storing massive activation datasets on disk [10] [11], incurring immense financial overhead. We posit the correct strategy involves storing these activations in an efficient, cost-effective, and easily accessible storage solution, such as object storage [12] [13] (see Appendix A for object storage cost-savings).
To resolve this central bottleneck, we introduce Activault, a robust and scalable activation data engine capable of efficiently generating, caching, and streaming activations directly to and from S3-compatible object storage. Activault significantly streamlines and amortizes the costs of training SAEs/transcoders/crosscoders/other interpreter models, empowers researchers to perform large-scale hyperparameter sweeps effortlessly, and crucially, enhances reproducibility. By making activations readily shareable over the internet, Activault enables any researcher, regardless of resources, to rapidly and affordably train high-quality interpreter models and accelerate interpretability science.
The Activault pipeline
Overview
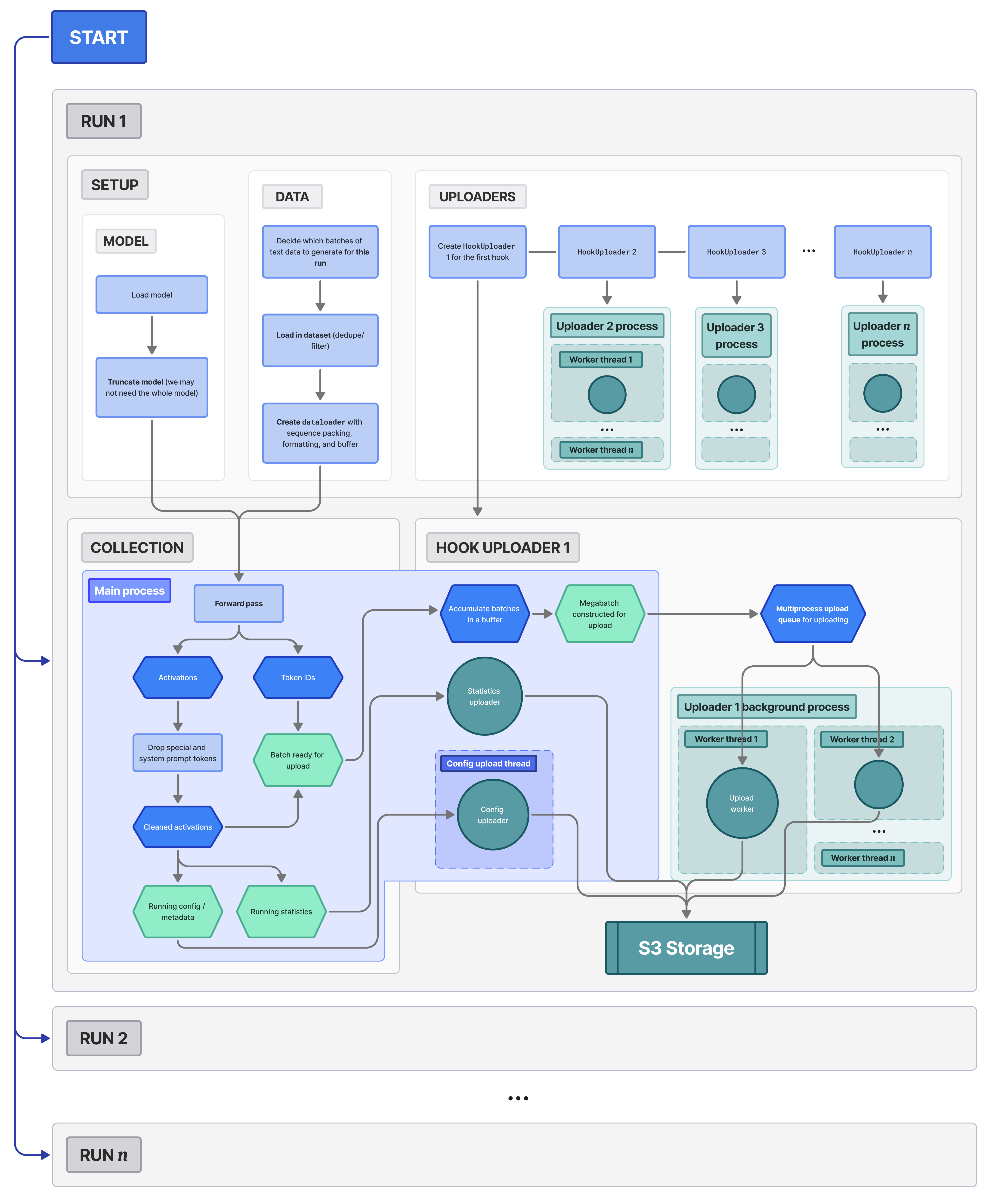 FIGURE 2: A diagram of the entire Activault writing pipeline, which we'll explain in subsequent sections.
FIGURE 2: A diagram of the entire Activault writing pipeline, which we'll explain in subsequent sections.
Here, we'll cover our pipeline for collecting and storing model activations. Three primary questions that motivated the design of our pipeline:
- How do we prevent uploading large amounts of data from bottlenecking our ability to collect activations?
- How can we add plug-and-play support for different datasets and models?
- How can we parallelize and utilize more compute effectively for activation collection?
The abstractions that allow us to do this efficiently and explainably are roughly as follows:
- Distributed jobs: multiple runs with their own copies of the model and slices of data execute in parallel.
- Setup stage: load in the model and dataset; create a custom dataloader per run to maximize throughput; instantiate the uploaders and their background processes.
- Collection: hook into the model; pass through and collect a final list of states, label with UUID and send to the uploaders.
- Upload: accumulate complete batches until enough to construct a file; send files to individual upload workers.
Setup
 FIGURE 3: Activault includes support for distributed runs.
FIGURE 3: Activault includes support for distributed runs.
We provide easy kickoff scripts for both Ray clusters and Slurm , where each worker receives a unique machine index and processes its own slice of the total data batches. The setup phase begins by calculating the exact batch distribution, namely how many batches each worker should process and their starting points so that we have an even distribution.
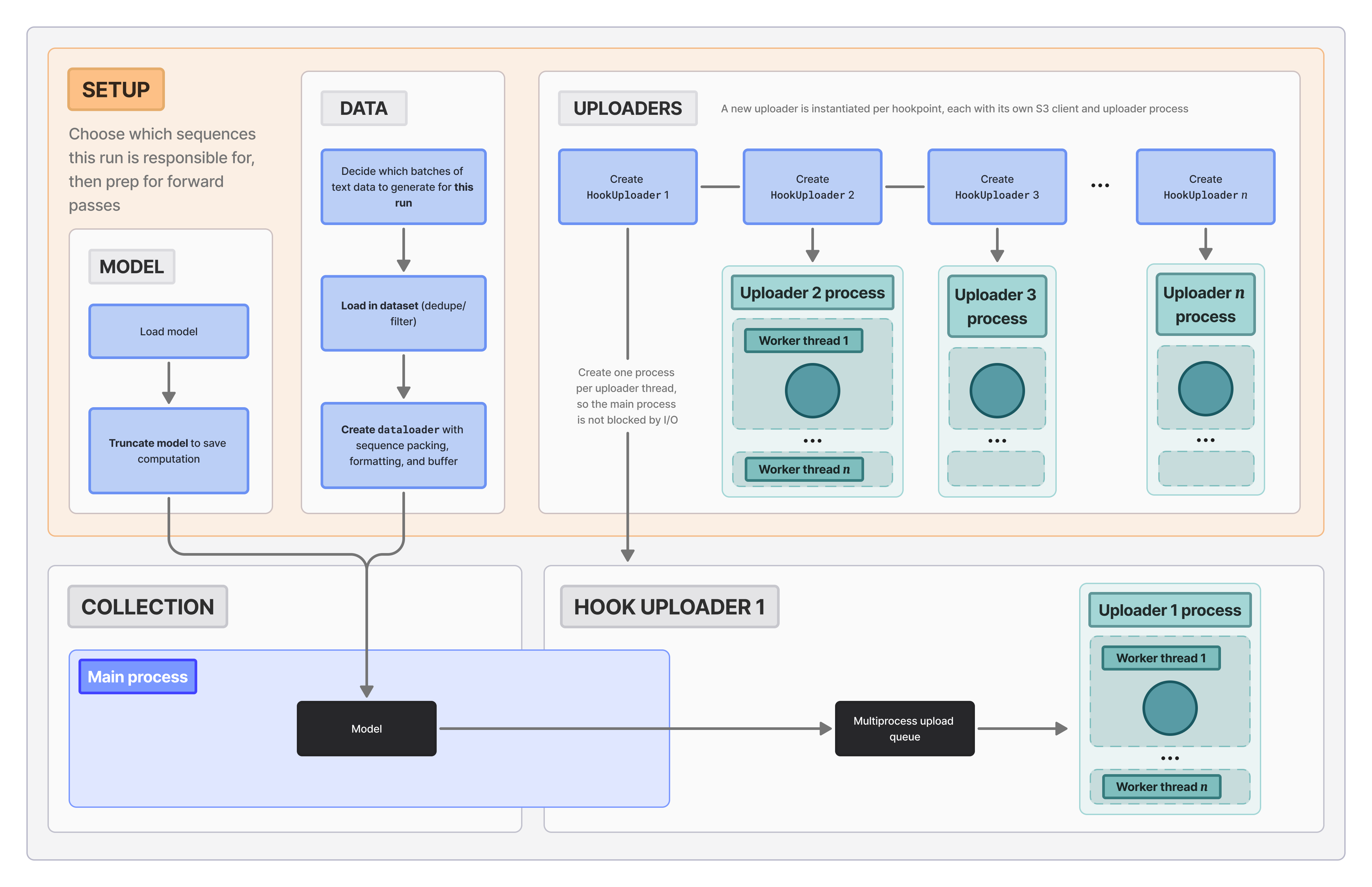 FIGURE 4: The three categories are: (1) load in model, (2) load in appropriate slice of data into dataloader, and (3) instantiate the HookUploaders and their background processes.
FIGURE 4: The three categories are: (1) load in model, (2) load in appropriate slice of data into dataloader, and (3) instantiate the HookUploaders and their background processes.
Each worker then independently loads its own copies of:
- The model (and tokenizer), with optional layer truncation based on the specified hooks. e.g., if the last layer we collect activations for is layer 12, we can discard the model beyond layer 12 to prevent wasted computation.
- The custom dataloader with sequence packing, so that we don't waste computation on pad tokens. We also add a buffer to account for when we drop activations for special tokens and system prompt tokens (which we cover in the collection stage below).
- Instantiate a HookUploader for each activation hook. Each uploader has its own S3 client and uploader process so that writing to S3 never bottlenecks the speed at which we can collect activations.
Collection
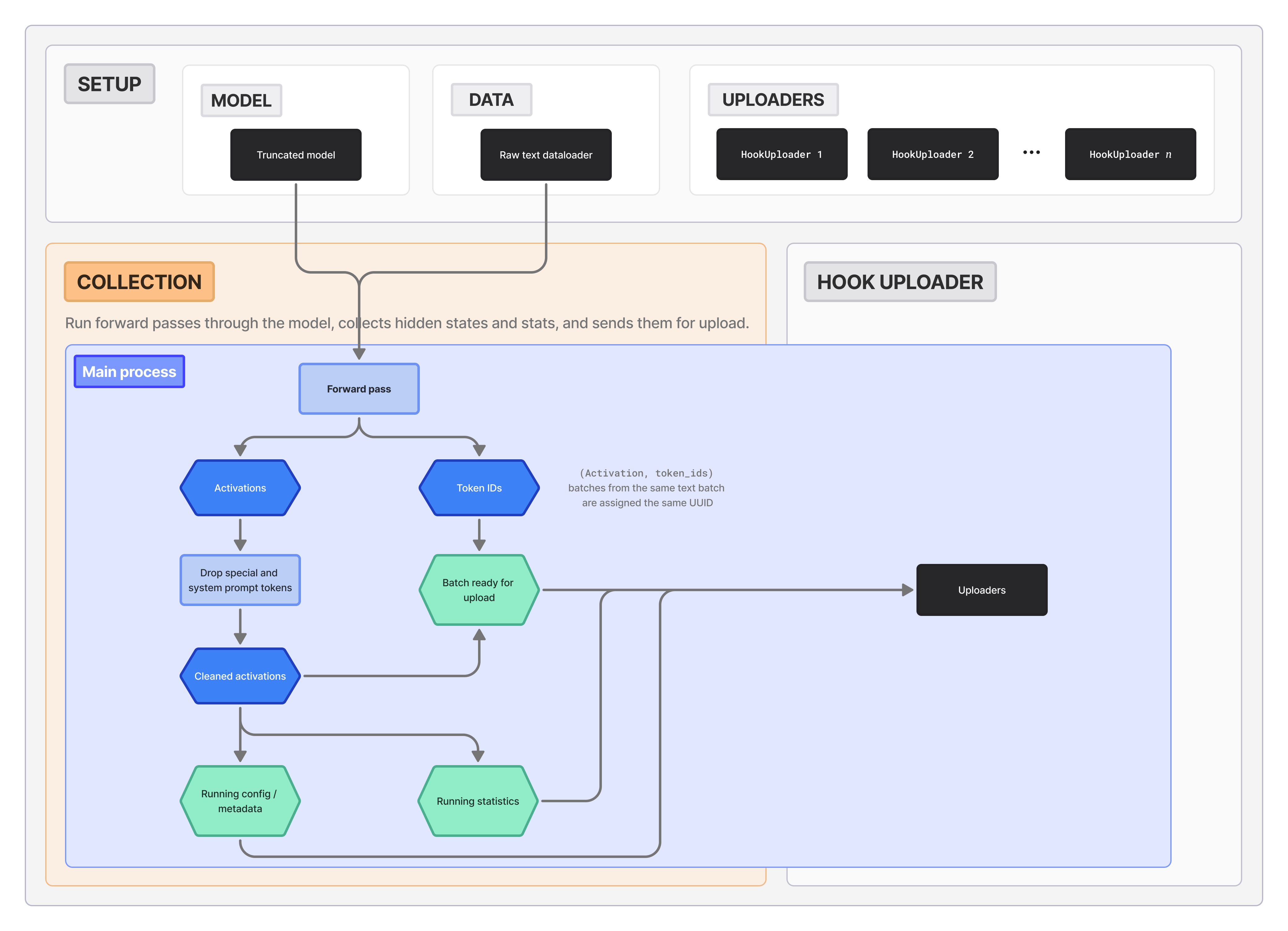 FIGURE 5: Activault's collection process is intentionally separated from any upload logic, which occurs primarily in the background. This modularization makes extensions and isolating bottlenecks easy.
FIGURE 5: Activault's collection process is intentionally separated from any upload logic, which occurs primarily in the background. This modularization makes extensions and isolating bottlenecks easy.
During the collection stage, we hook into the model to collect the activations that we care for. We provide support for collecting MLP and attention outputs, as well as model hidden states. Each forward pass, we get activations for every hookpoint we specify (e.g., hidden states at 8 different layers).
# Forward pass
outputs = model(**batch, output_hidden_states=True)
# Extract activations
activations = {}
for hook in hooks:
if hook in hook_activations:
activations[hook] = {
"states": hook_activations[hook]["states"],
"input_ids": batch["input_ids"],
}
Importantly, we drop repetitive and noisy activations that may negatively impact interpreter model training after the forward pass. Concretely, this means that the forward pass will contain chat templating (if requested), as it should, but we will not save the activations that come from chat templating. Otherwise, it could be the case that a nontrivial portion of our final activations are all the same chat template tokens, adding noise to our final dataset.
cleaned_activations = {}
for hook in hooks:
cleaned_input_ids, cleaned_states = loader.clean_batch(
activations[hook]["input_ids"], activations[hook]["states"]
) # drop all special and template tokens
cleaned_activations[hook] = {
"states": cleaned_states,
"input_ids": cleaned_input_ids,
}
Before sending our batch to their uploaders, we assign all activations from the same batch one shared UUID. This allows for matching activations across different layers when needed, e.g., for training crosscoders.
We also collect activation statistics, in particular the average norm of activation vectors and the population mean and standard deviation vectors. These statistics can be used to normalize inputs to interpreter models for improved training stability. We apply Welford's online algorithm for computing variance to keep accurate running estimates for the statistics.
Upload
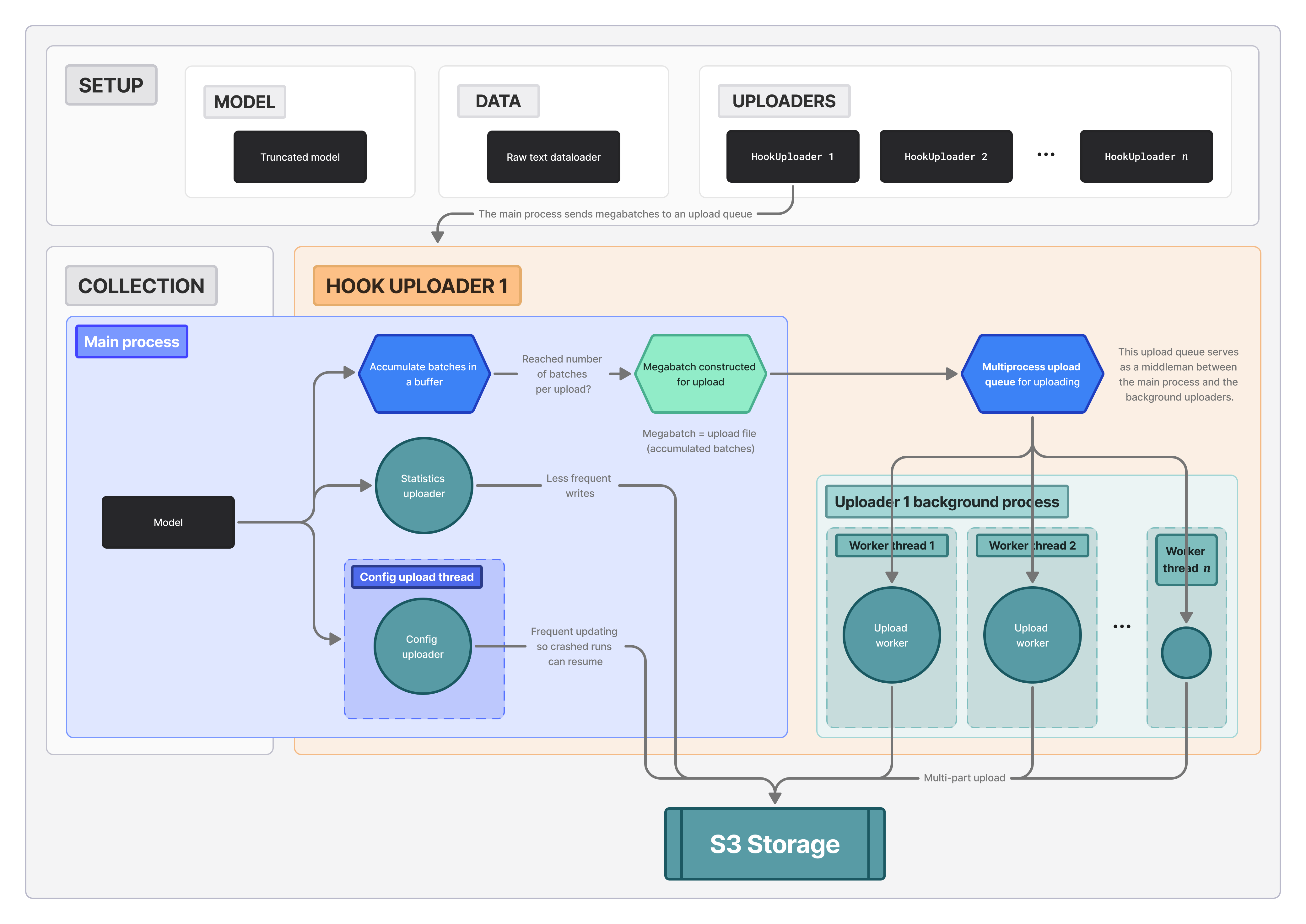 FIGURE 6: HookUploaders are the bulk of the upload process. They (1) accumulate batches in the main process, (2) package megabatches and send them to a multiprocess queue, where (3) the workers compete for and upload these files to S3.
FIGURE 6: HookUploaders are the bulk of the upload process. They (1) accumulate batches in the main process, (2) package megabatches and send them to a multiprocess queue, where (3) the workers compete for and upload these files to S3.
There are two separate uploaders for the config file (so resuming runs is easy) and the computed running statistics (to checkpoint regularly). These jobs are small compared to the HookUploaders, which handle model activations.
This upload stage happens simultaneously with the collection stage, in the background across several threads within separate processes. The flow is best summarized as:
- Each HookUploader receives a new cleaned batch of activations and token ids from the collection phase (in the main process).
- It keeps receiving these cleaned batches until it has enough to make a file (each file contains multiple batches so as to not hit rate limits for number of write requests).
- Once it has enough for a file, it concatenates these with the most recent UUID filename into a megabatch.
- Megabatches are placed in a multiprocess queue, so that the workers within this HookUploader's upload process can greedily take and upload into the S3 storage.
- Upload workers utilize multipart uploads for a supposed improved throughput, although in practice we haven't observed this to make a difference[14].
This way, even if an individual file takes 30+ seconds to upload, the collection process observes no slowdowns. We show performance profiling below.
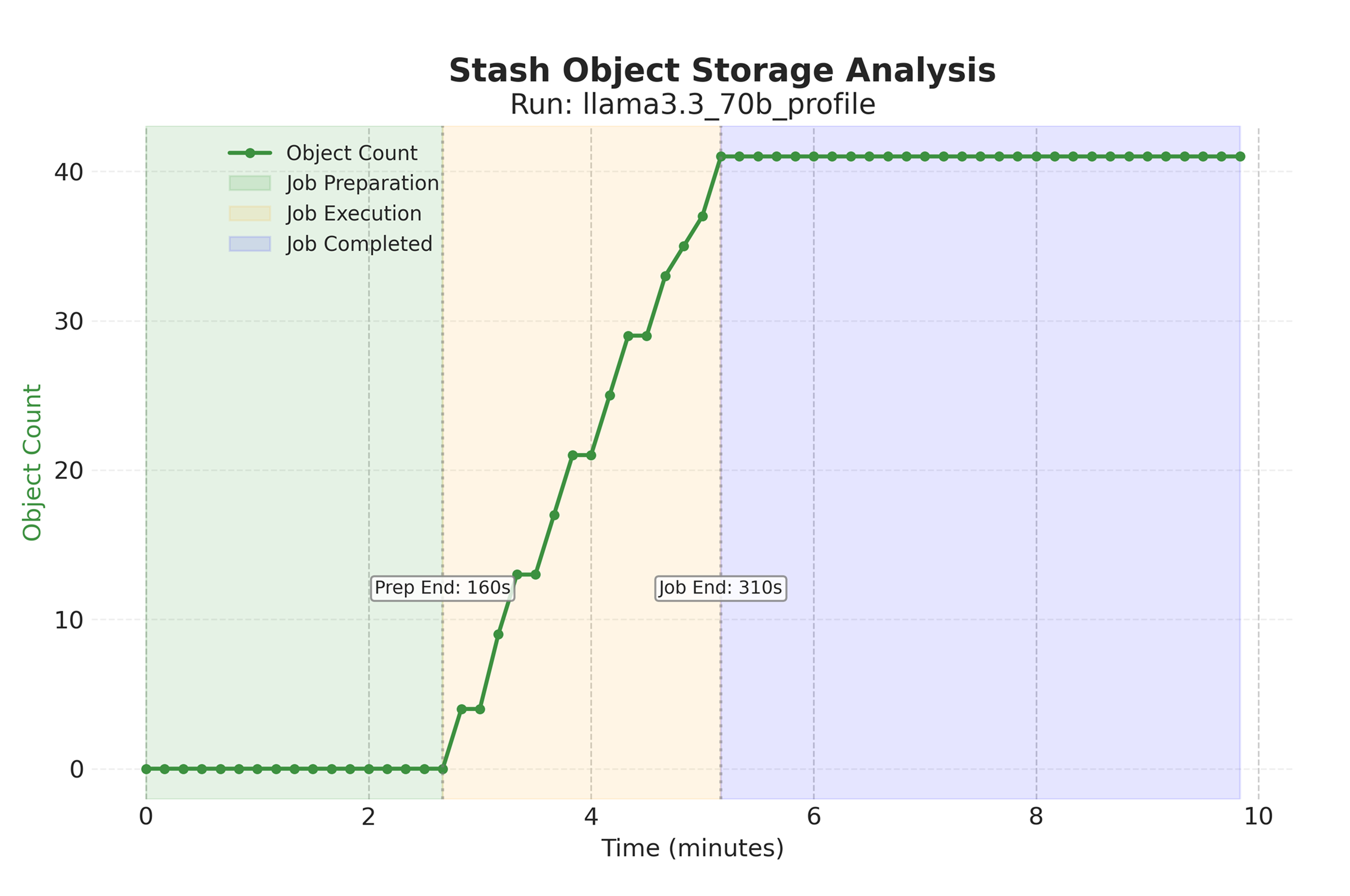 Figure 7: Performance profiling of write cache for 8 megabatches of activations from 4 hookpoints of LLaMa 3.3 70B. Object writes do not occur significant additional time overhead.
Figure 7: Performance profiling of write cache for 8 megabatches of activations from 4 hookpoints of LLaMa 3.3 70B. Object writes do not occur significant additional time overhead.
Each hook's data should be stored in its own directory:
s3://{bucket}/{run_name}/
├── cfg.json # Collection config and model info
└── {hook_name}/
├── metadata.json # Shape and dtype info
├── statistics.json # Running statistics
└── {uuid}--{n}.pt # Megabatch files
We also provide a CLI tool to easily navigate and inspect the uploaded files to verify that the pipeline executed successfully.
RCache: Reading from S3
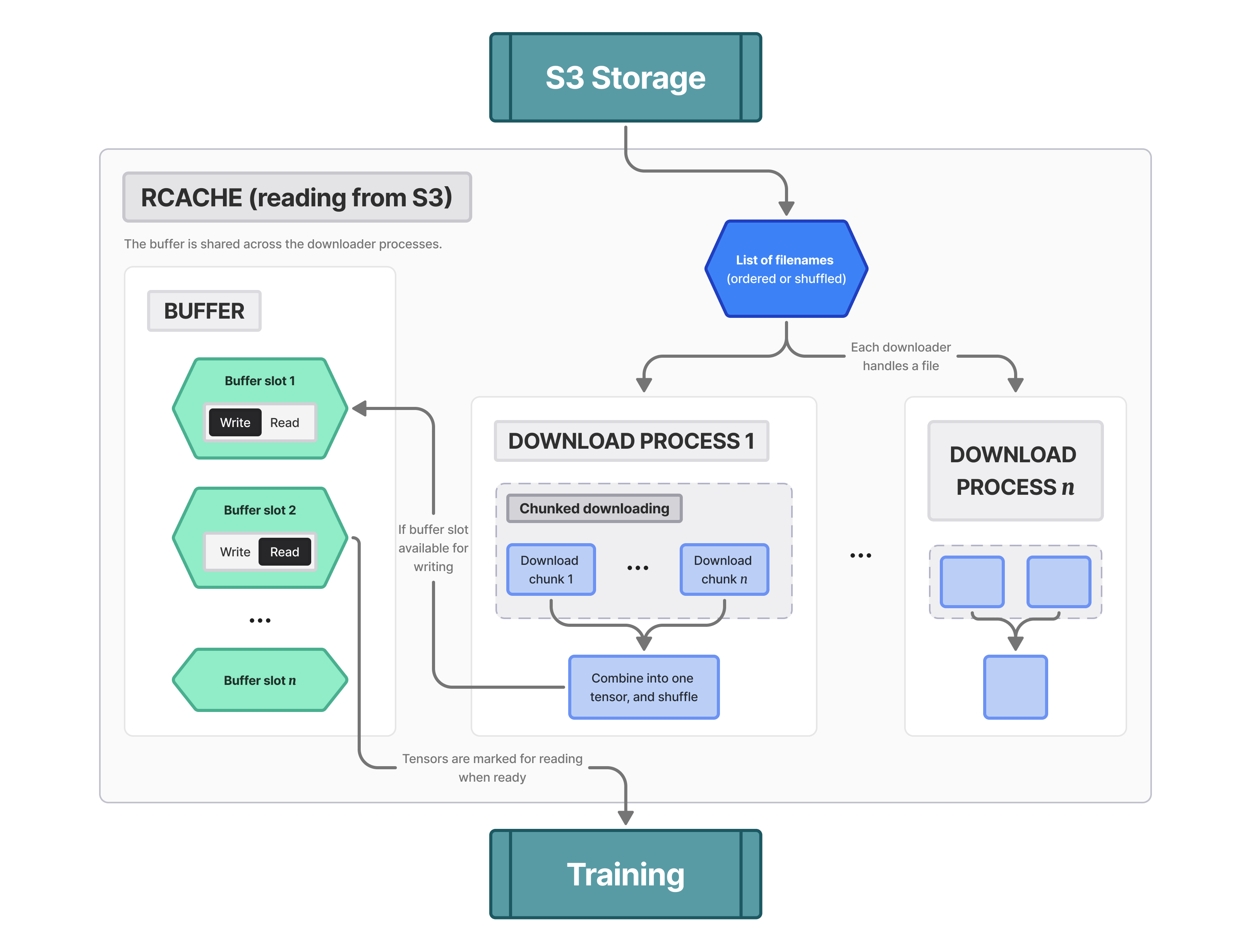 FIGURE 8: Activault also provides an optimized way of reading from S3 for training jobs.
FIGURE 8: Activault also provides an optimized way of reading from S3 for training jobs.
RCache provides a simple interface for efficiently streaming large activation datasets from S3 without memory or I/O bottlenecks. While you process the current megabatch, the next ones are downloaded asynchronously. Under the hood:
- RCache operates with a simple buffer swap mechanism. By default, it pre-allocates 2 slots in shared memory for megabatches (though you can configure more). These slots dance between two states - writeable and readable. When you start up, both slots are writeable, waiting for data.
- Multiple worker processes compete to grab files from S3. A worker claims a writeable slot, downloads its assigned file in async chunks, deserializes the PyTorch tensor, and drops it into shared memory. Once done, it flags the slot as readable and moves on.
- The main process is consuming these readable slots, copying out the data, and recycling them back to writeable.
After a brief initial load period, processing should never be bottlenecked by the I/O. We show performance profiling below.
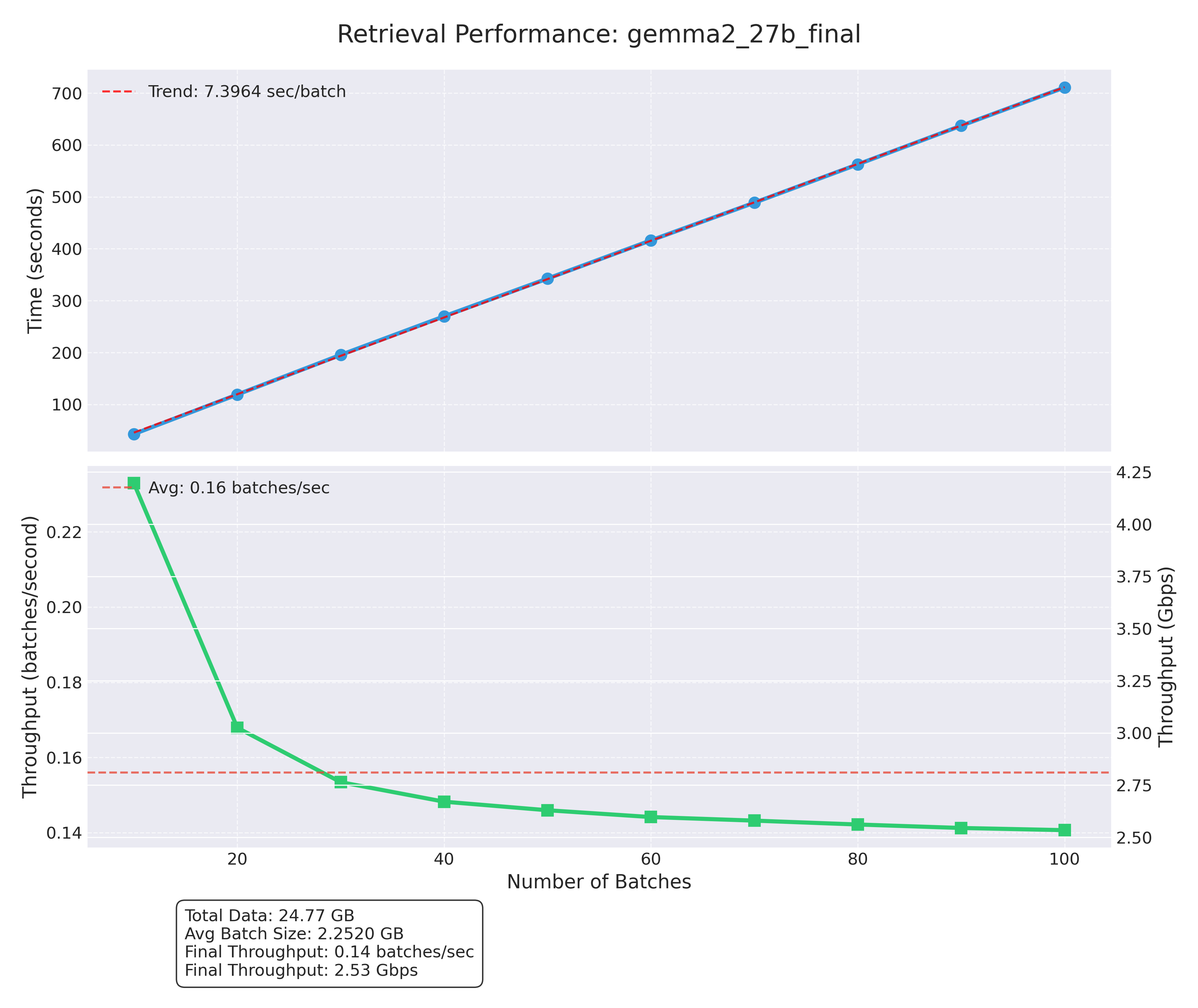 FIGURE 9: Performance profiling of read cache for 100 megabatches of activations from Gemma 2 27B. RCache achieves consistently high throughput for downloading activations.
FIGURE 9: Performance profiling of read cache for 100 megabatches of activations from Gemma 2 27B. RCache achieves consistently high throughput for downloading activations.
Shuffling
There are various clever ways of shuffling a large dataset [15], although we find that two simpler methods suffice (so as long as the sequence length and batch size is reasonably large). First, we randomize the order of S3 files before we start downloading (unless you explicitly want to preserve order). Then, within each megabatch, we shuffle all tokens across both sequences and batches using randperm (reminder that a file/megabatch = multiple batches).
RCache is built to keep memory usage flat while maximizing throughput. It handles multiple S3 prefixes, validates compatibility, and manages its own cleanup.
Conclusion
Activault significantly lowers the barriers to large-scale interpretability research by tackling the core challenge of activation data management. It provides a streamlined setup, high throughput, and cost-effective storage while ensuring reproducibility, allowing researchers to efficiently experiment, share insights, and build on each other's work. By making interpreter model training more accessible, Activault helps streamline interpretability research and hopefully will help improve our understanding of frontier AI models.
We are releasing Activault as a community tool, and welcome contributions and active maintainers.
Acknowledgements
The inspiration for Activault comes from a LessWrong post on using S3 to train a SAE on GPT2-small < 30 minutes [13]. Big shoutout to the Nebius support team for assistance scaling Activault on their solution. In particular, we would like to highlight the contributions of solutions architects Rene Schonfelder and Mikhail Mokrushin.
References
- DeepSeek-AI, Daya Guo, Dejian Yang et al. (2025).
- Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang (2025).
- Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and Cunningham, Hoagy and Turner, Nicholas L and McDougall, Callum and MacDiarmid, Monte and Freeman, C. Daniel and Sumers, Theodore R and Rees, Edward and Batson, Joshua and Jermyn, Adam and Carter, Shan and Olah, Chris and Henighan, Tom (2024).
- Gao, Leo and la Tour, Tom Dupré and Tillman, Henk and Goh, Gabriel and Troll, Rajan and Radford, Alec and Sutskever, Ilya and Leike, Jan and Wu, Jeffrey (2024).
- Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kramár, János and Dragan, Anca and Shah, Rohin and Nanda, Neel (2024).
- Karvonen, Adam and Rager, Can and Lin, Johnny and Tigges, Curt and Bloom, Joseph and Chanin, David and Lau, Yeu-Tong and Farrell, Eoin and McDougall, Callum and Ayonrinde, Kola and Wearden, Matthew and Conmy, Arthur and Marks, Samuel and Nanda, Neel (2025).
- Wu, Zhengxuan and Arora, Aryaman and Geiger, Atticus and Wang, Zheng and Huang, Jing and Jurafsky, Dan and Manning, Christopher D. and Potts, Christopher (2025).
- Eleuther AI (2025).
- Marks, Samuel and Karvonen, Adam and Mueller, Aaron (2024).
- Bloom, Joseph and Tigges, Curt and Chanin, David (2024).
- Eluether AI (2025).
- Nebius AI.
- Ewington-Pitsos, Louka (2024).
- Hardin, Chris (2018).
Appendix
A. Object storage cost-savings
| Aspect | Nebius Disk Storage (Network SSD Disk) | Nebius S3 Object Storage |
|---|---|---|
| Storage Cost | ~$74,448.90 / month | ~$15,414.55 / month |
| Write Operations | – (cost is included in disk price) | ~$3.57 (1,048,576 PUTs at $0.0034/1,000) |
| Read Operations | – (no separate charge) | ~$300.65 (≈1,073,741,824 GETs at $0.00028/1,000) |
| Egress Traffic | Free within the same region | Free internally / ~$15,728.64 if egressed externally (1,048,576 GiB × $0.0150/GiB) |
| Total Monthly Cost | ~$74,448.90 | ~$15,718.77 (internal access) ~$31,447.41 (with external egress) |
| Aspect | Amazon EBS (gp3) | Amazon S3 (Standard) |
|---|---|---|
| Storage Cost | $83,886.08 / month | $22,320.26 / month |
| Write Cost | Included | $0.52 (for 1 GB objects) |
| Read Cost | Included | $0.42 (assuming 1 MB objects) |
| Total Monthly | $83,886.08 / month | $22,321.20 / month |